

如何用手牌历史日志训练扑克机器人
说到扑克机器人,它们对你的“坏运气故事”毫不关心。它们甚至不喜欢所谓的“运气波动”。它们关心的是日志——那些纯文本、带时间戳、记录桌位、筹码深度、金额的详细文件,才是它们真正关注的重点。
你知道的,那些大多数玩家只是为了以后翻看一下糟糕河牌跟注而保存的文件。我曾经通宵翻阅这些记录,直到手牌在眼前混成一片,“UTG加注到$3”看起来已经不像是一个操作,而像是矩阵中的裂缝。
在这些文件中,扑克机器人开始学习。这就是扑克机器人手牌历史训练的起点——将原始、混乱的日志转化为AI战略知识的基础。
清理与解析扑克手牌历史日志
手牌历史日志非常混乱。PokerStars、GGPoker、WSOP——它们各有各的怪癖。有时盲注会写在文件开头,有时埋在第三行,有时是看起来来自2004年的格式(因为它的确是)。
第一步任务就是清理它们。把筹码量统一成大盲数,把操作格式统一,把牌面转化为机器可读取的二进制向量。机器人并不会“看到”黑桃A——它看到的是52位数组中第12位的“1”。是不是很浪漫?

解析得越干净,进入机器人“大脑”的垃圾就越少。我甚至曾花三天时间追踪一个解析错误,因为它让一半的小盲出现了虚假加注。机器人因此在翻牌前弃掉了口袋K。尴尬吗?绝对。收获呢?更多。
将手牌历史日志转化为扑克机器人训练数据
这里的关键在于:扑克机器人不需要你充满激情的策略演讲来打出好牌。它需要的是结构化的状态-动作对。
我们会把每一手牌拆解为决策点:底池大小、位置、筹码深度、公共牌结构、前序下注。再加入一些人工计算值,比如底池赔率、隐含赔率、SPR(筹码与底池比)、弃牌权益。然后是标准动作:弃牌、跟注、加注,以及不同类型的下注。
如果是监督学习,机器人就会模仿。这是行为克隆,来自强牌手的成千上万、数以百万计的决策。就像在教一只鹦鹉说话,只不过这只鹦鹉有时候会在CO位轻3-Bet。这是扑克机器人手牌历史训练中的关键环节——日志中的结构化操作会转化为可执行的决策模型。
如果是强化学习,手牌历史更像是一面镜子。它们不是主要燃料(自我博弈能生成更丰富的数据),但它们能帮助模型在真实环境下调整行为。
在扑克机器人训练中使用CFR与深度学习
反事实遗憾最小化(CFR)依然是王者。机器人会在每一个决策点计算如果没做某个动作会有多少遗憾,然后逐步调整。这样重复十亿次,你就得到了博弈论最优(GTO)的打法。
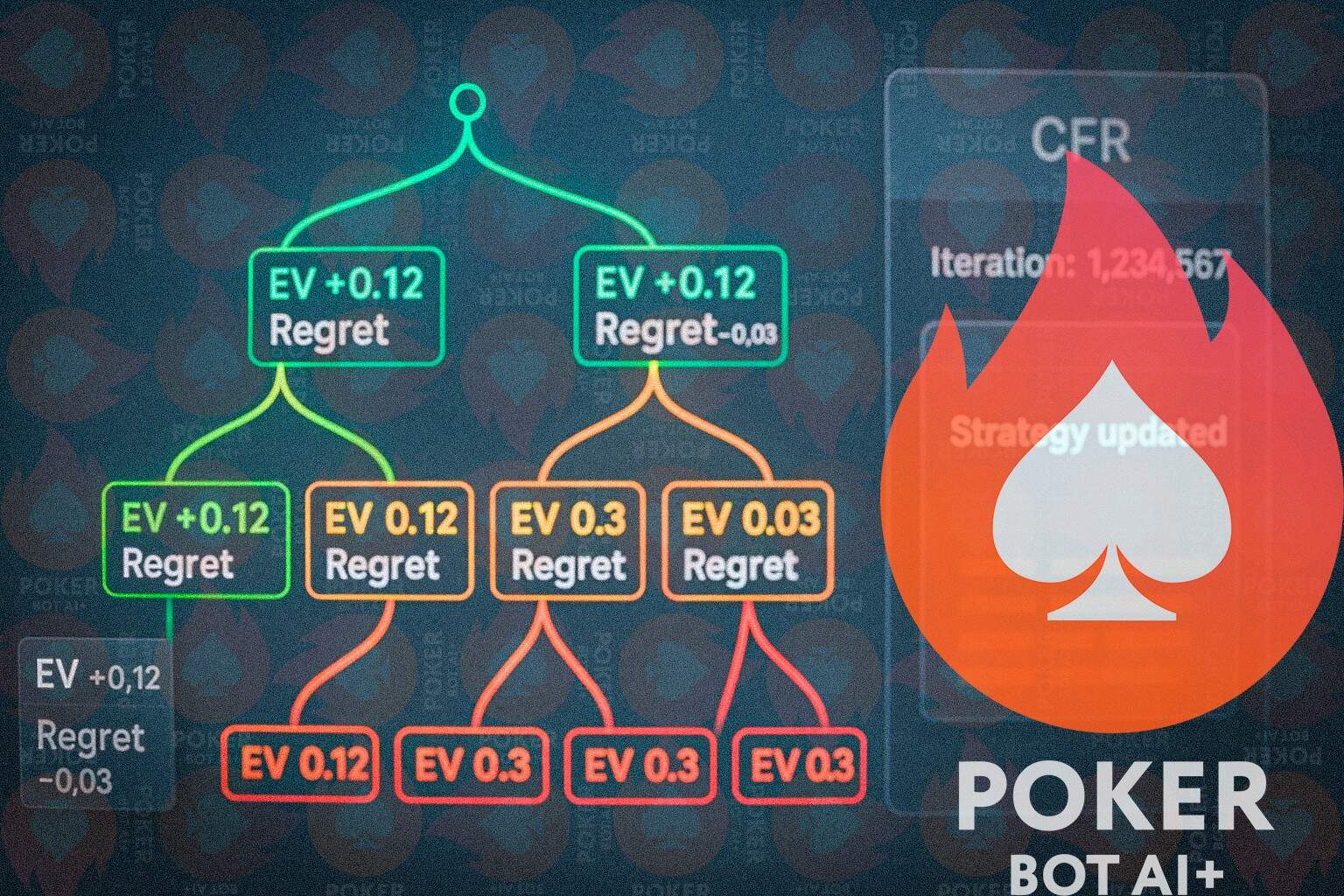
然后,深度强化学习会处理更棘手的部分。DeepStack用神经网络处理未来博弈,Pluribus则能适应6人桌的混乱。最强的扑克AI最终会是混合型机器人——核心是GTO,边缘则是利用性打法。
这里的手牌历史呢?它们是校准工具。它们展示了真实玩家的实际操作,让机器人在有真钱的桌上打得更保守。
错误、漏洞与人为因素
训练机器人不仅仅是数字运算,还包括调试背后的数学逻辑。
我曾见过机器人因为特征向量中一张杂牌被误标,导致在翻牌前弃掉口袋A。我还遇到过机器人在限注德州中诈唬全下,因为下注规模归一化模块出了问题。
每一个解析和特征工程的错误都会不断放大。你的扑克AI算法不会比输入的数据更聪明。垃圾输入,垃圾AI输出。
关键是:手牌历史并不精确。它们带有玩家群体的偏见——过度弃牌、诈唬不足、怪异的线路。如果盲目用它们训练,机器人会学到这些特性。有时候这很好(针对特定群体的利用性优势),有时候则是陷阱。
训练完成后的扑克机器人测试与评估
训练完成后,你会得到一个模型。但它还不是一个完整的机器人。
你需要一个接口来将桌上的实时状态输入模型;需要下注逻辑能在训练集之外的不舒适局面中表现稳定;需要后备策略,以便模型信心不足时能回到更安全的基线。
最终产物不仅仅是一个数学模型,而是一个软件——一个可以测试、评估、甚至对弈的扑克AI项目。
在研究领域,你会用AIVAT方差削减方法来估算机器人的胜率。如果是私下测试,你可能会让它打10万手牌,然后希望图表曲线向上。
然后,你看它打牌

这才是有趣的地方。
你看着机器人做了一件奇怪的事——在干燥的翻牌面用第三对过牌加注。你检查日志,它是在利用数据集中隐藏的某种倾向:这种类型的对手在多人底池中面对激进打法时过度弃牌。
你看到它慢打口袋A,而你从未教过它这么做。你看到它在一个你会弃牌的场景中做出了英雄跟注。有时候它的操作很精彩,有时候则彻底崩盘。
这正是关键所在。一个通过手牌历史训练的机器人,会本能地学习日志中每一个决策。这正是扑克机器人手牌历史训练的核心——把无数记录下的手牌策略转化为桌上可执行的打法。数千名玩家的模式被平滑、加权、转化为概率。
它并不完美。但我们也一样。